做爬虫的, 要有自己的工具来发现网络世界的动态, 对信息保持一份敏感, 对数据存有一颗敬畏之心.
项目名称: ClericPy/watchdogs
项目初衷
-
统一关注.
平时可能会追剧追小说追综艺, 关注疫情实况, 订阅一些博客, 但是网站多了太分散, 所以需要一份 Timeline 方便浏览.
-
解放双手.
满足对日常信息变化的订阅, 并提供主动提醒功能, 从不断刷网页判断更新中解放双手. 简而言之, 信息索取由被动转为主动.
-
体验新事物.
主要功能
- 适用于: 追剧, 追星, 追小说漫画, steam 降价, 博客更新, 服务翻车, 疫情实况, 定向新闻或搜索结果等场景的提醒.
- 根据定制解析规则, 关注网页特定数据的变化, 记录更新时间与历史数据, 并提供对应 URL 进行跳转. 所有爬虫执行在协程环境下, 抓取 / 存储 / 回调与整个 Web 服务相互独立不阻塞.
- 通过可视化 Web UI 快速配置爬虫的下载器与解析器参数, 目前熟练操作以后, 配置一个抓取规则大约耗时 3 分钟.
- 结合前段时间写的解析规则持久化模块 uniparser, 将解析方式存储在数据库中, 避免每次新增爬虫都要发布代码. 该库虽然涵盖的解析方式很多, 但大部分库都是惰性引用, 开销并不算太大.
- 总的来说, 就是将大量爬虫解析器的耦合代码归纳起来, 然后把变量部分入库保存, 实现解析规则持久化.
- 定制化提醒方式. 默认支持了『Server 酱』和 RSS 的订阅, 以及适配手机的 Lite 页面.
- 快速部署.
- 默认配置只需要 pip 安装后
python3.7 -m watchdogs即可启动 Web App, 配置文件与日志文件存放在 $HOME/watchdogs 目录下, 若没有指定mysql的db_url, 则使用sqlite数据库也存放在该目录. - 内存占用大约 80 MB, Linux 系统下如果安装
uvloop, 性能非常顺畅. - 也可以将 watchdogs 作为第三方库来进行私人订制, 只需要调制好
watchdogs.Config中的各项原始变量, 然后执行watchdogs.init_app()即可拿到app: Fastapi对象, 该对象可以进行二次绑定 routes, 不过尽量不要作为 sub_app 使用, 否则会错过 startup 和 shutdown 事件的回调函数, 需要另行调用.
简单上手
-
安装 (pip)
pip install -U watchdogs
-
部署 (python3.7+)
python3.7 -m watchdogs
-
使用
通过浏览器访问相应地址即可
详细使用
启动参数
- 查看帮助:
python -m watchdogs -- -h - 以下参数除了命令行启动时使用, 作为第三方库引用时也可以使用, 而实际使用中在通过
watchdogs.init_app初始化 app 实例前, 直接修改watchdogs.Config对应配置更方便. - db_url:
sqlite / mysql / postgresql所支持的db_url, 也就是 databases 所支持的.
若是不指定, 则会使用
sqlite:///$HOME/watchdogs/storage.sqlitePostgreSQL 没有进行实机测试.
- password:
初始化的密码, 一般不需要指定, 除非密码被人给破了, 所以要提前指定进行修改, 否则在网页端就可以修改.
- mute_std_log:
忽略
stdout, stderr上日志的显示
- mute_file_log:
日志不再保存到 $HOME/watchdogs 目录.
- md5_salt:
md5 加盐用的参数, 全局 md5 鉴权时使用, 一般不需要指定, 除非要多处部署分布式, 保证加盐统一.
- config_dir:
配置文件目录, 用来存放配置文件和日志文件的地方, 如果没有指定数据库, 则也会存放
sqlite数据文件. 不指定的话, 默认为 $HOME/watchdogs
- use_default_cdn:
如果 Config.cdn_urls 没有指定, 并且指定了 use_default_cdn, 将使用来自 staticfile.org 的在线 js / css CDN 链接.
- uvicorn_kwargs:
uvicorn 启动参数, 常用的有 port, host, access_log 等. 例如:
python -m watchdogs --port=9999 --host=127.0.0.1 --access-log=False
Web 界面
- 通过
python3.7 -m watchdogs启动时, 默认网页访问的是 http://127.0.0.1:9901- 首次访问会有个配置新密码的过程.
- 先看一下已经配置过的首页样式
[Tab] Tasks
首页, 任务列表.
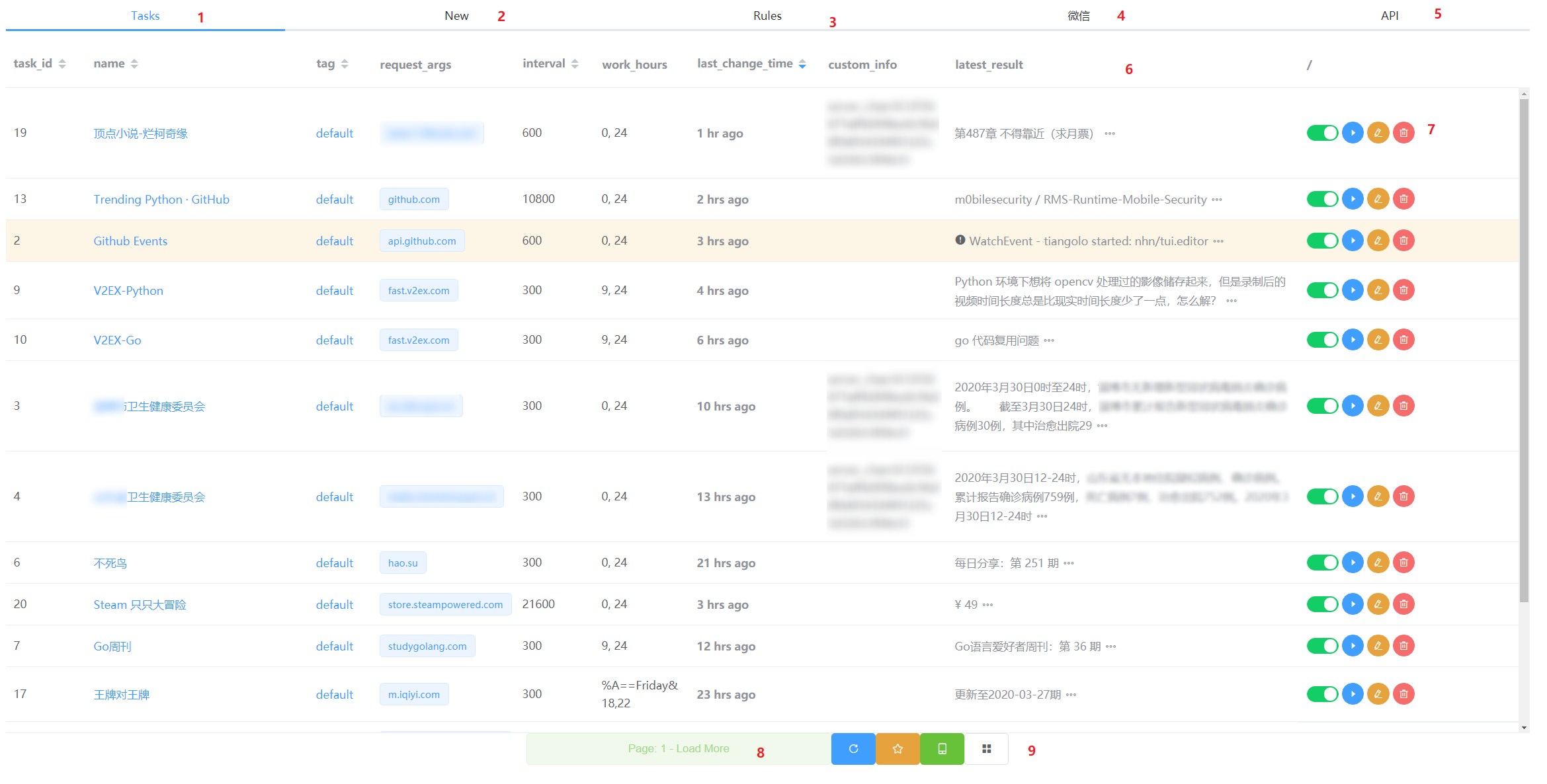
- 也就是首页. 直观展示全部任务列表, 每页默认 30 个.
- 新建任务的页面.
- 规则列表, 按照 host 分类.
- 由
Config.custom_tabs变量配置的页面, 展示为一个自定义网址的iframe - 由
Config.custom_tabs变量配置的页面, 展示的是fastapi默认的/docs - 任务列表的表头
task_id: 自增数字, 用来做主键的.name: 任务名称, 唯一索引, 可以通过名字找到一个任务.tag: 任务的标签, 为下面的 RSS 和 lite 页面做的分类过滤, 也为当前任务列表做的过滤, 点击即可过滤.request_args: 请求参数, 是一个兼容requests / aiohttp库的字典, 同时支持retry,ssl等参数.interval: 抓取频率的参数, 类型为整型, 单位是秒.work_hours: 爬虫工作时间, 支持多种形式, 比如包含标准strftime格式的与或非逻辑(==, !=, &, |).- 0, 24: 表示当前小时处于 range(0, 24) 之间.
- [18, 19, 20]: 表示每天的 18 19 20 这三个小时内才进行抓取.
- %A==Friday: 表示每周五.
- %m-%d==03-13: 每年的 3 月 13 日.
- %H==05: 每天早上 05:00 ~ 05:59
- %w==5;20, 24: 表示每周五的 20:00 ~ 23:59.
- [1, 2, 15]&%w==5: 每周五的 1 点 2 点和 15 点.
- %w==5|%w==2: 每周二和周五.
- %w!=6&%w!=0: 只要不是周六或周日的任意一天.
last_change_time: 上次更新时间. 本链接点击后会展示三个属性: 上次抓取时间, 下次抓取时间, 上次更新时间.custom_info: 自定义信息. 这个会影响到抓取发现变化时候的回调, 分三种情况.- 内容是无规律没有
:的:- 如果指定了 name 为 ’’ 的 Callback, 则会唤起该回调函数进行处理本任务.
- 如果没有指定上述默认回调的话, 则该内容纯粹就是个笔记本记录一点描述.
- 内容里有
::- 会按
:进行一次 split, 左边是回调名称, 右边则是回调的参数, 具体回调可以通过继承watchdogs.callbacks.Callback自动绑定. - 目前默认已经支持了的是
server_chan, 也就是 Server 酱 进行回调, 参数则是回车或空格分割的多个 Token.
- 会按
- 内容是无规律没有
latest_result: 最新结果.- 点击链接会跳转采集到的
url参数指定的网址, 如果未指定, 则会跳转到任务 meta 里的origin_url地址. - 点击三个点按钮的话, 则显示的是整个结果列表, 包括抓取到的时间.
- 点击链接会跳转采集到的
- 注意: 有一行的任务是橘黄色的, 表示任务抓取出错了, 具体错误可以点击最新结果那列里的感叹号标识, 抓取报错的情况下, 一般不会入库存储算做最新结果, 除非是找不到规则.
- 任务操作栏.
- 任务开关, 如果是关闭的任务, 除非强制抓取, 否则将不会再被抓取.
- 强制抓取. 跳过抓取间隔队列, 强制抓取一次本任务, 会刷新该任务各项 meta, 也会影响下次抓取时间的调度.
- 修改任务. 修改该行任务的各项 meta 信息.
- 快捷方式: 双击该行.
- 删除任务. 会有一次确认弹窗.
- 加载下一页.
- 四个页面操作的小按钮.
- 刷新本页. 会重新从第一页获取任务列表.
- RSS 链接. 使用加盐 Token 来避开 Cookie 的验证, 适合给 RSS 阅读器进行订阅.
- 由于默认抓取循环的扫描间隔是 60 秒, 所以 RSS 更新的频率不要低于 60 秒.
- 适配移动端 Lite 页面链接. 使用加盐 Token 来避开 Cookie 的验证. 点击顶部大标题可以跳回首页.
- 自定义链接. 存放于
watchdogs.Config.custom_links的快捷方式, 方便记录一些经常需要访问的地址. 默认已经放了修改密码与查看日志的页面.
任务信息
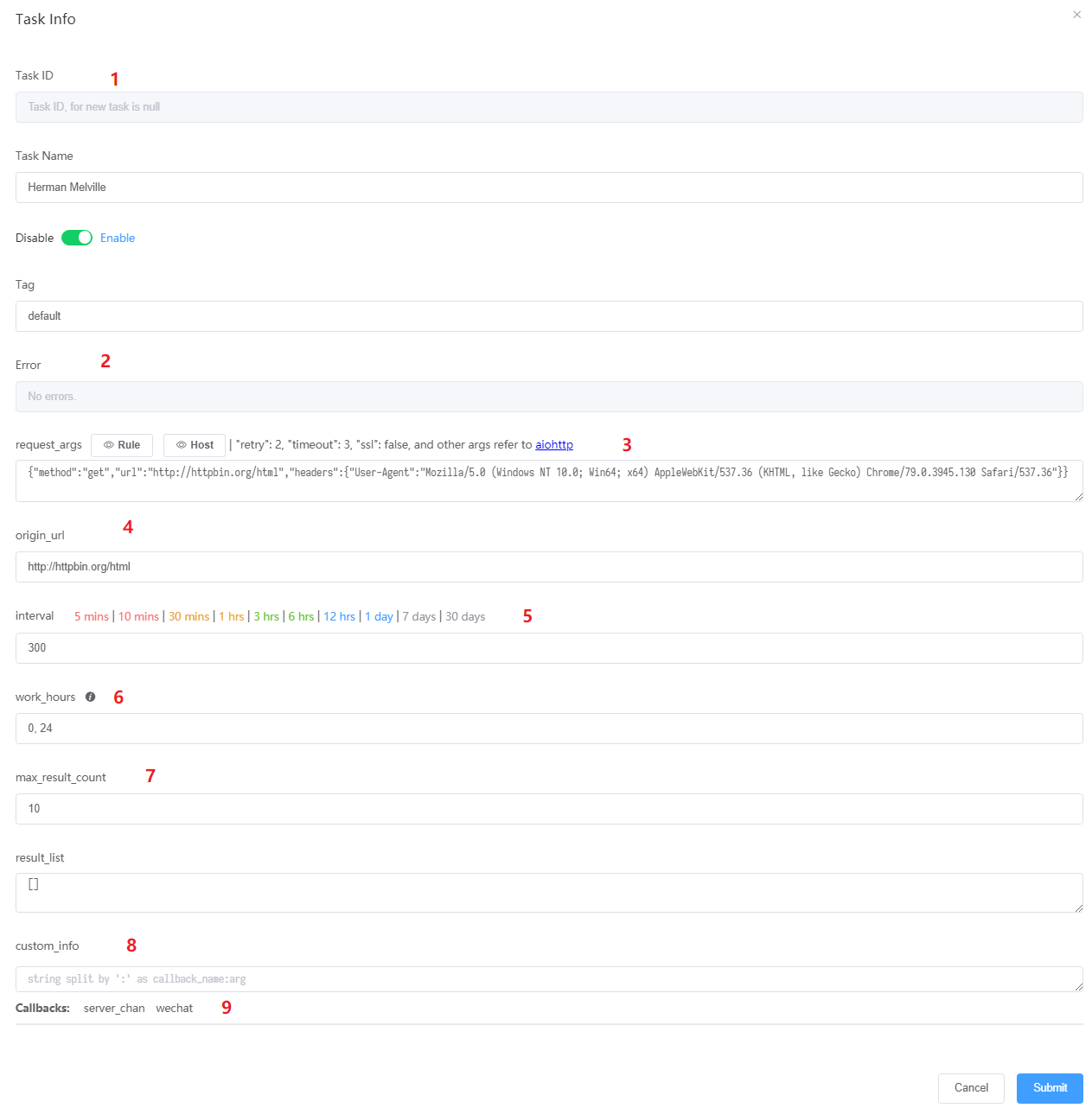
- 任务的自增 ID, 不可修改.
- 任务信息页面如果是新建任务时打开的, 这里为空, 会由后端自动生成.
- 任务信息如果是任务列表双击打开的, 这里会是一个整数, 用于定位到数据库中的位置, 方便修改 meta 信息
- 错误信息, 出错时会导致正行变成橘红色.
- 修改
request_args的一些方便复制粘贴的常用参数, 比如超时和重试, 以及忽略ssl验证避免证书报错. - 当抓取结果里没有
url的时候,origin_url会用来跳转. - 快速选择抓取间隔, 省去计算秒数的时间.
- 前文提过的
work_hours文档点击信息图标即可看到了. - 历史列表的最大保存数量, 避免保存太多浪费存储.
[Tab] New
此处是新建任务时使用
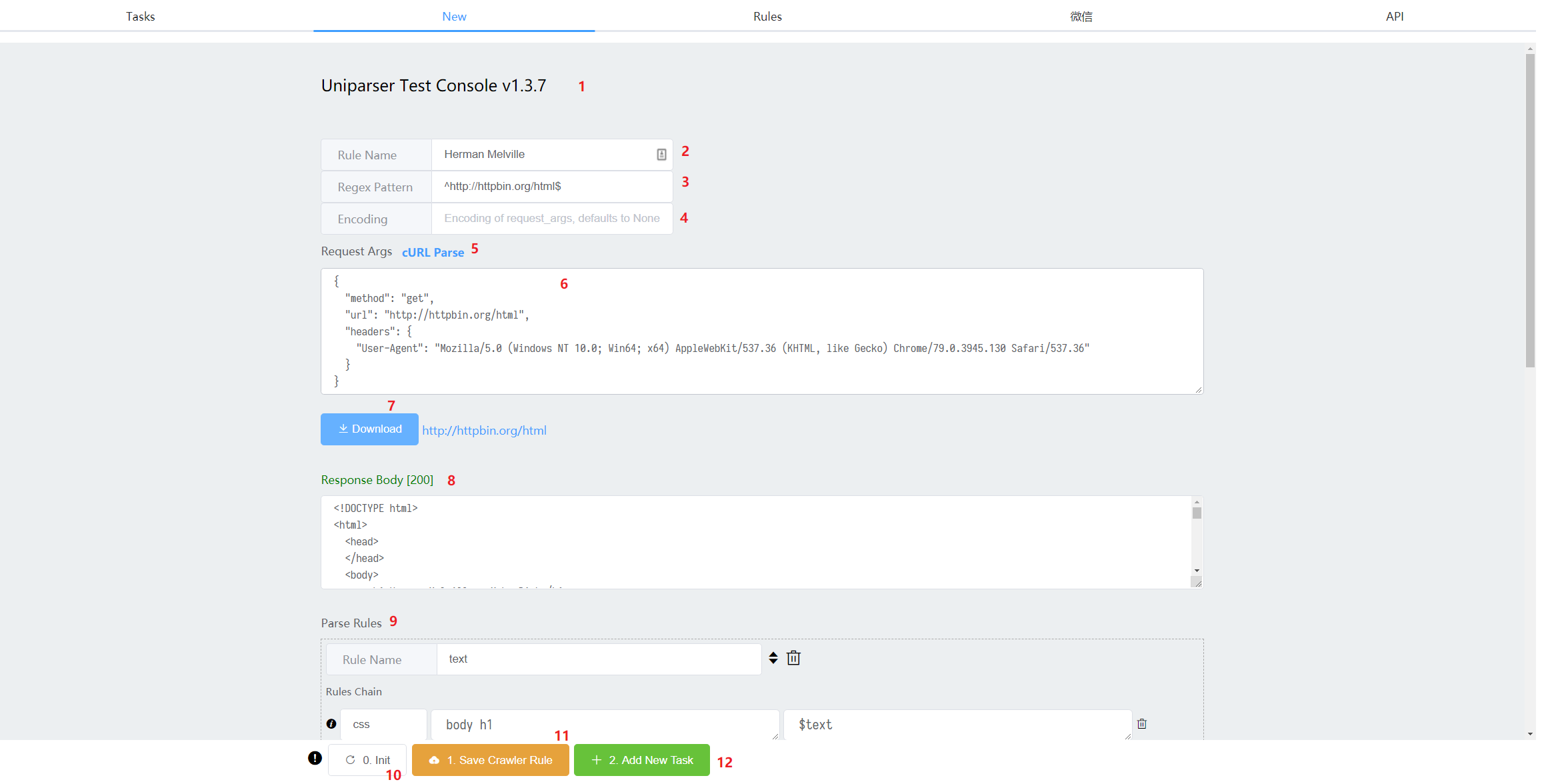
- 基于 uniparser 子 app 的
iframe托管, 所以可以直接去其官网查看具体使用文档. - 规则的名称, 一般留空, 等待点击 [Download] 按钮以后会自动获取一个, 到时候再略微修改即可.
- 用于识别网址是否匹配该规则的正则表达式, 一般留空, 使用下文所述的 [
cURL Parse] 功能即可自动生成, 为了匹配更多网址, 可能要稍微修改其中部分变量为.*? - 编码, 默认不指定的话会由
requests或者aiohttp自带的chardet库进行识别. - 通过此处来设置
request_args参数会节省很多力气, 点击后填入 URL 或者一段标准cURL字符串 ( 比如在Chrome devtools console -> Network -> Copy as cURL), 将自动转为 requests 请求的标准字典.- 并且如果 Regex Pattern 参数为空, 则自动填入一段, 然后由用户自行微调.
- 可以在此处对请求的字典参数进行细致调整
- 注: 因为这里是配置的规则层面的
request_args, 在真正发起请求的时候, 将会被 Task 层面的request_args所覆盖.
- 注: 因为这里是配置的规则层面的
- 下载按钮. 点击后如果 Rule Name 没有配置, 则会自动填入请求结果里的 title 或 h1 标签内容, 否则填入一个当前时间戳的字符串.
- 发送请求后的响应主体. 会显示请求的状态码和 body.
- 具体的解析规则. 配置方式可以参考 uniparser 官网.
- 每次点击 Parse 按钮即可查看已经配置的解析结果.
- 初始化一份解析规则方便二次修改. 多次点击会在两种 Demo 之间切换.
- 一种是 CSS 选择器解析方式的 Demo
- 另一种则是 XML 解析的 Demo, 这种主要是用来处理 RSS.
- 保存当前配置好的抓取规则.
- 一定要确保解析结果符合要求:
- 结果里一定要有
text字段 - 结果里可以有
url字段, 如果没有则会被Task.origin_url所替代 - 结果可以是字典, 也可以是列表里的字典, 如果是列表会被倒序存入历史列表.
{'text': 'some text', 'url': 'http://example.com'}[{'text': 'some text', 'url': 'http://example.com'}, {'text': 'some text2', 'url': 'http://example2.com'}]
- 结果里一定要有
- 一定要确保解析结果符合要求:
- 创建新任务.
- 默认会根据当前规则填入一些空白参数, 略做微调即可.
- 提交后可以去 Tasks 页面点强制抓取, 不用等下一次循环.
- 具体任务各项 meta 信息在页面上基本都有文档来参考.
- 所以, 最简单的创建一个任务来参考的方式就是:
- 点击
Init按钮 - 点击
Download按钮 - 点击
Save Crawler Rule按钮 - 点击
Add New Task按钮 - 点击提交即可
- 点击
[Tab] Rule
规则列表页面, 按照 host name 进行归类
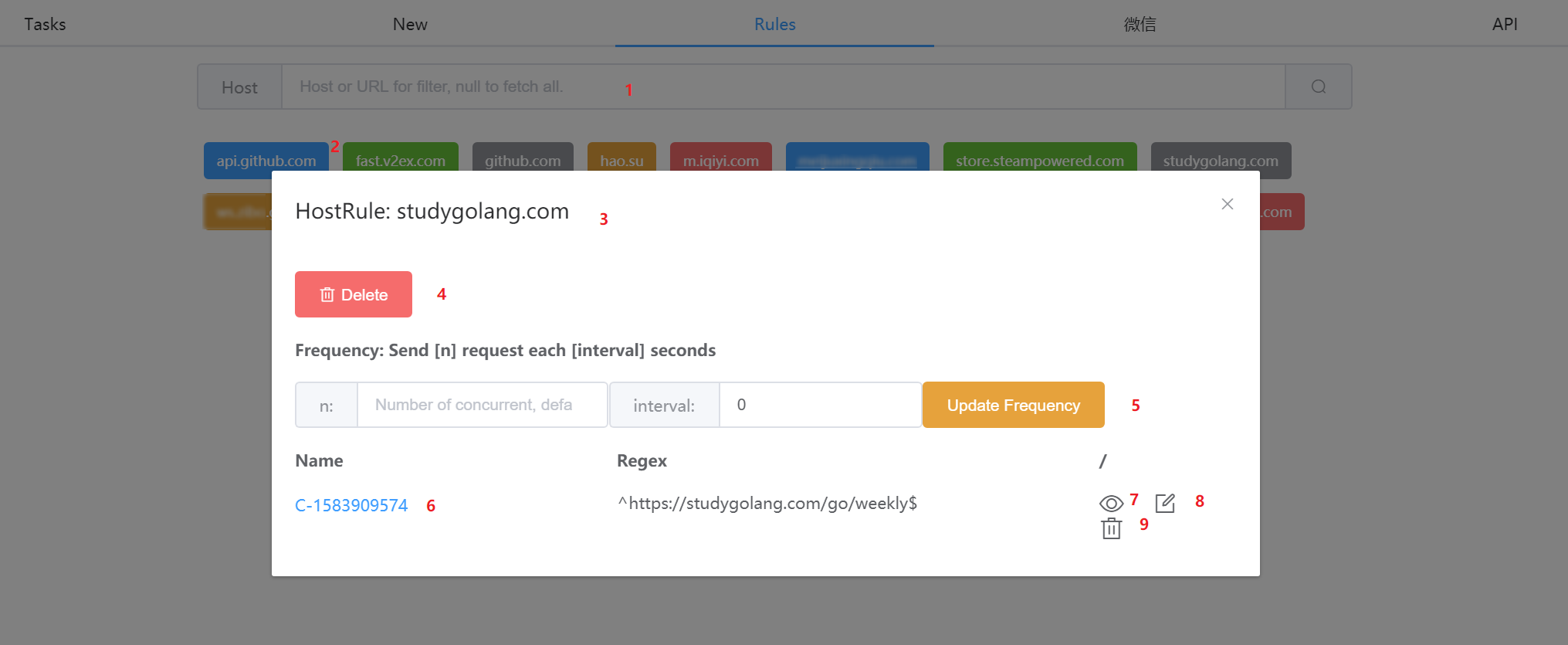
- 可以输入 host 片段对所有 host 进行过滤, 按下回车或点击搜索按钮则会重新去服务器获取.
- 每个 host 是一个可以点击的彩色 Tag, 点击后出现详细信息的弹窗
- 规则信息弹窗, 在数据库中也是按 host name 索引的
- 删除整个
HostRule, 整行删除 - 控制该 host 下的所有请求抓取频率, 避免因为抓取频率过快而触发反爬
- 默认不限制并发数和抓取间隔
- 举个例子, n 设置为 3, interval 设置为 1, 表示 1 秒里最多发起 3 次请求
- 之前新建任务时候起的倒霉名字, 如果想修改, 点击这里就会跳转过去, 修改完再次 Save 即可.
- 注意: 因为
CrawlerRule在HostRule里面是拿 name 做 key 的, 所以会有一次覆盖确认.
- 注意: 因为
- 和上面一样, 点击后跳转到该条
CrawlerRule的修改页面 - 将该条抓取规则直接当成
JSON修改, 适合较熟悉的使用, 在uniparser里, 所有规则都是可持久化的, 因为它们都继承了dict类 - 删除该抓取规则, 因为是二次弹出的页面, 所以不太需要二次确认了, 点击就会删除
自定义使用
from fastapi import FastAPI, Request
from uvicorn import run
from watchdogs import Config, init_app
# 更新默认的 Config 为自定义参数
Config.db_url = 'mysql+pymysql://root:password@172.1.2.3:3306/db?charset=utf8mb4'
app: FastAPI = init_app()
@app.get('/new_page')
def new_page(request: Request):
return {'method': request.method}
run(app, **Config.uvicorn_kwargs)
结语
整个项目框架搭起来用了大概半个月, 然而后续小 bug 层出不穷, 再加上很多功能优化, 断断续续发了很多版本改了很长时间. 其实之前也尝试过做了一个 onwebchange 的库, 但是各种设计都太稚嫩, 所以想了想本着 2.0 的思路重新从 uniparser 开始搞, 也算把很久以前存放在 todoist 里的想法清理了一遍.
英文文档远没有中文文档详细, 遇到问题可以通过 Github issues.
截止到 2020-03-31, 功能基本已经完整, 之后不再计划太频繁的非 bug 更新.